Paralelismo en el Procesador
Paralelismo es una
función que realiza el procesador para ejecutar varias tareas al mismo tiempo.
Es decir, puede realizar varios cálculos simultáneamente, basado en el
principio de dividir los problemas grandes para obtener varios problemas
pequeños, que son posteriormente solucionados en paralelo.
PARALELISMO A NIVEL DE INSTRUCCIONES

El
paralelismo a nivel de instrucción consiste en una técnica que busca que la
combinación de instrucciones de bajo nivel que ejecuta un procesador puedan ser
ordenadas de forma tal que al ser procesadas en simultáneo no afecten el
resultado final del programa, y más bien incrementen la velocidad y aprovechen
al máximo las capacidades del hardware. Un pipeline (canalizador) de
instrucciones es el que permite que por cada ciclo de reloj del procesador
múltiples instrucciones se encuentren en distintas fases de ejecución.
El paralelismo a nivel
de instrucción es aplicable dentro de cada bloque básico (secuencia de
instrucciones sin saltos). Sin embargo, la longitud media de un bloque básico es
de 3 a 6 instrucciones lo que reduce bastante su posible aprovechamiento. Una
técnica para mejorar el aprovechamiento del ILP dentro de un bucle se conoce
como des enrollamiento de bucles. El des enrollamiento de bucles consiste en
entrelazar la ejecución de instrucciones de varias iteraciones de un bucle. Al
tratarse de instrucciones no relacionadas no generan dependencias y permiten un
mejor aprovechamiento de la arquitectura segmentada.
PARALELISMO A NIVEL DE DATOS
 Paralelismo a nivel de datos es un paradigma de la programación concurrente que
consiste en subdividir el conjunto de datos de entrada a un programa, de manera
que a cada procesador le corresponda un subconjunto de esos datos. Cada
procesador efectuará la misma secuencia de operaciones que los otros
procesadores sobre su subconjunto de datos asignado. En resumen: se distribuyen
los datos y se replican las tareas.
Paralelismo a nivel de datos es un paradigma de la programación concurrente que
consiste en subdividir el conjunto de datos de entrada a un programa, de manera
que a cada procesador le corresponda un subconjunto de esos datos. Cada
procesador efectuará la misma secuencia de operaciones que los otros
procesadores sobre su subconjunto de datos asignado. En resumen: se distribuyen
los datos y se replican las tareas.
Idealmente, esta ejecución simultánea de operaciones, resulta en una
aceleración neta global del cómputo.
El paralelismo a nivel de datos es un paradigma suficientemente adecuado
para operaciones sobre vectores y matrices, dado que muchas de ellas consisten
en aplicar la misma operación sobre cada uno de sus elementos.
PARALELISMO DE TAREAS
El paralelismo de tareas es la característica de un programa
paralelo en la que cálculos completamente diferentes se pueden realizar en
cualquier conjunto igual o diferente de datos. Esto contrasta con el
paralelismo a nivel de datos, donde se realiza el mismo cálculo en distintos o
mismos grupos de datos. El paralelismo de tareas por lo general no escala con
el tamaño de un problema.
PARALELISMO A NIVEL DE BITS
Es cuando se aumenta el
tamaño de la palabra en la computadora, hacer esto reduce el número de
instrucciones que son necesarias para ejecutar una instrucción en la cual sus operandos
son más grandes que su tamaño de palabra.
MULTI THREADINGS
Arquitecturas que consideran
la ejecución simultánea de diferentes hilos de ejecución en un mismo
procesador: paralelismo a nivel de hilo o thread level parallelism (TLP). En
estas arquitecturas:
- Diferentes hilos de ejecución comparten las unidades funcionales del procesador (por ejemplo, unidades funcionales).
- El procesador debe tener estructuras independientes para cada uno de los hilos que ejecuta, como registro de renombre o contador de programa, entre otros.
- Si los hilos pertenecen a diferentes procesos, el procesador debe facilitar mecanismos para que puedan trabajar con diferentes tablas de páginas.
Arquitecturas
multihilo, también conocidas como super-threading. Esta fue la siguiente de las
variantes TLP que apareció. El modelo de pipeline del procesador se extiende
considerando también el concepto de hilo de ejecución. En este caso, el
planificador (que escoge cuál de las instrucciones empezará en este ciclo)
tiene la posibilidad de escoger cuál de los hilos de ejecución empezará la
instrucción siguiente en el ciclo siguiente. Consiste en compartir los recursos
en el tiempo, es decir, en un ciclo concreto y en una etapa concreta del
procesador, solo se pueden encontrar instrucciones de un mismo hilo.
MULTI NUCLEO

El concepto de multi núcleo,
como su nombre indica, consiste en replicar m núcleos diferentes dentro de un
procesador. Cada núcleo acostumbra a tener una memoria caché de primer nivel
(de datos e instrucción) y puede tener una memoria de segundo nivel (suele ser
unificada: datos más instrucciones). Aparte de los núcleos, el procesador
acostumbra a tener otros componentes especializados y ubicados fuera de estos.
Habitualmente, existen los siguientes: una memoria de tercer nivel, un
controlador de memoria y componentes para hacer
procesamiento de gráficos, entre otros. Todos estos componentes (incluidos los
núcleos) se encuentran conectados mediante una red de interconexión. Esta es el
medio físico y lógico que permite enviar peticiones de un componente a otro.
Como se ha introducido, uno de los componentes de un
multinúcleo fundamental es el controlador de memoria. Este gestiona las
peticiones de acceso al subsistema de memoria que hace el resto de componentes
(tanto lecturas como escrituras).
CLASIFICACION DE FLYNN
La taxonomía de Flynn
es la clásica clasificación usada en computación paralela, la cual usa ideas
familiares al campo de la computación convencional para proponer una taxonomía
de arquitecturas de computadores. Esta es una de las más viejas, pero es la más
conocida hasta nuestros días. La idea central que se usa se basa en el análisis
del flujo de instrucciones y de datos, los cuales pueden ser simples o
múltiples, originando la aparición de 4 tipos de máquinas. Es decir, esta
clasificación está basada en el número de flujos de instrucciones y de datos
simultáneos que pueden ser tratados por el sistema computacional durante la
ejecución de un programa. Un flujo de instrucción es una secuencia de instrucciones
transmitidas desde una unidad de control a uno o más procesadores. Un flujo de
datos es una secuencia de datos que viene desde un área de memoria a un
procesador y viceversa. Se pueden definir las variables ni y nd como el número
de flujos de instrucciones y datos, respectivamente, los cuales pueden ser
concurrentemente procesados en un computador. Según eso, las posibles
categorías son:
SISD
(Single Instruction Stream, Single Data Stream)

Esta
representa la clásica máquina de Von-Neumann, en la cual un único programa es
ejecutado usando solamente un conjunto de datos específicos a él. Está
compuesto de una memoria central donde se guardan los datos y los programas, y
de un procesador (unidad de control y unidad de procesamiento). En esta
plataforma sólo se puede dar un tipo de paralelismo virtual a través del
paradigma de multitareas, en el cual el tiempo del procesador es compartido
entre diferentes programas. Así, más que paralelismo lo que soporta esta
plataforma es un tipo de concurrencia. Los PC son un ejemplo de máquinas que
siguen este tipo de procesamiento.
SIMD
(Single Instruction Stream, Multiple Data Stream)
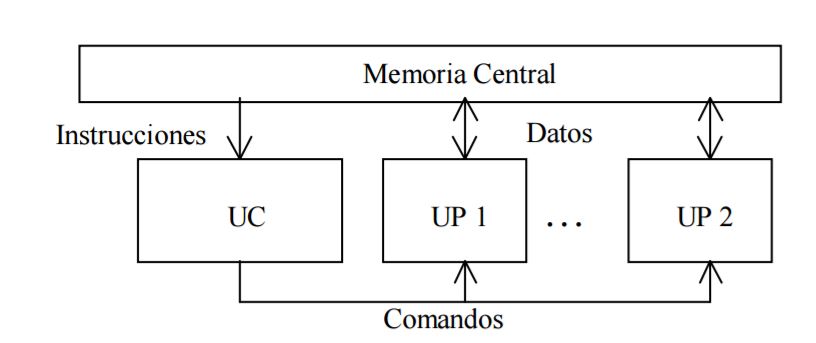
Arreglo
de elementos de procesamiento, todos los cuales ejecutan la misma instrucción
al mismo tiempo. El enfoque de paralelismo usado aquí se denomina paralelismo
de datos. Los arreglos de procesadores son típicos ejemplos de esta clase de
arquitectura. En estas arquitecturas, un controlador recibe y decodifica
secuencias de instrucciones a ejecutar, para después enviarlas a múltiples
procesadores esclavos. El arreglo de procesadores procesa los datos que llegan
a los diferentes procesadores, usando la instrucción enviada por el
controlador. Los procesadores están conectados a través de una red. Los datos a
tratar pueden estar en un espacio de memoria que es común a todos los
procesadores o en un espacio de memoria propio a cada unidad de procesamiento.
Todos los procesadores trabajan con una perfecta sincronización. SIMD hace un
uso eficiente de la memoria, y facilita un manejo eficiente del grado de
paralelismo. La gran desventaja es el tipo de procesamiento (no es un tipo de
procesamiento que aparece frecuentemente), ya que el código debe tener una
dependencia de datos que le permita descomponerse.
MISD (Multiple Instruction Stream, Single
Data Stream)

Estas
son computadoras con elementos de procesamiento, cada uno ejecutando una tarea
diferente, de tal forma que todos los datos a procesar deben ser pasados a
través de cada elemento de procesamiento para su procesamiento.
Implementaciones de esta arquitectura no existen realmente, excepto ciertas
realizaciones a nivel de mecanismos de procesamiento tipo encauzamiento
(pipelining en inglés) (internamente en los procesadores RISC, etc.) o sistemas
de tolerancia a fallas. Muchos autores consideran que esta clase no corresponde
a un modo de funcionamiento realista. Otros autores consideran que representan
el modo de procesamiento por encauzamiento.
La idea es descomponer
las unidades de procesamiento en fases, en donde cada una se encarga de una
parte de las operaciones a realizar. De esta manera, parte de los datos pueden
ser procesados en la fase 1 mientras otros son procesados en la 2, otros en la
tres, y así sucesivamente. El flujo de información es continuo y la velocidad
de procesamiento crece con las etapas. Este tipo de clasificación de Flynn
puede ser incluida dentro de la clasificación SIMD si se asemeja el efecto de
estas máquinas, al tener múltiples cadenas de datos (los flujos) sobre las
etapas de procesamiento, aunque también puede ser visto como un modo MIMD, en
la medida de que hay varias unidades y flujos de datos y cada etapa está
procesando datos diferentes.
MIMD (Multiple Instruction Stream,
Multiple Data Stream)
Es el modelo más
general de paralelismo, y debido a su flexibilidad, una gran variedad de tipos
de paralelismo puede ser explotados. Las ideas básicas son que múltiples tareas
heterogéneas puedan ser ejecutadas al mismo tiempo,



Comentarios
Publicar un comentario